crawlergo 源码学习
项目介绍
项目地址:https://github.com/Qianlitp/crawlergo
crawlergo是一个使用chrome headless模式进行URL收集的浏览器爬虫。它对整个网页的关键位置与DOM渲染阶段进行HOOK,自动进行表单填充并提交,配合智能的JS事件触发,尽可能的收集网站暴露出的入口。内置URL去重模块,过滤掉了大量伪静态URL,对于大型网站仍保持较快的解析与抓取速度,最后得到高质量的请求结果集合。
crawlergo 目前支持以下特性:
- 原生浏览器环境,协程池调度任务
- 表单智能填充、自动化提交
- 完整DOM事件收集,自动化触发
- 智能URL去重,去掉大部分的重复请求
- 全面分析收集,包括javascript文件内容、页面注释、robots.txt文件和常见路径Fuzz
- 支持Host绑定,自动添加Referer
- 支持请求代理,支持爬虫结果主动推送
crawlergo 是现在用的比较多的动态爬虫了,一般就是 crawlergo + xray 组合来进行漏扫,现在就来看看 crawlergo 的源码。
项目结构
画了一下导图:
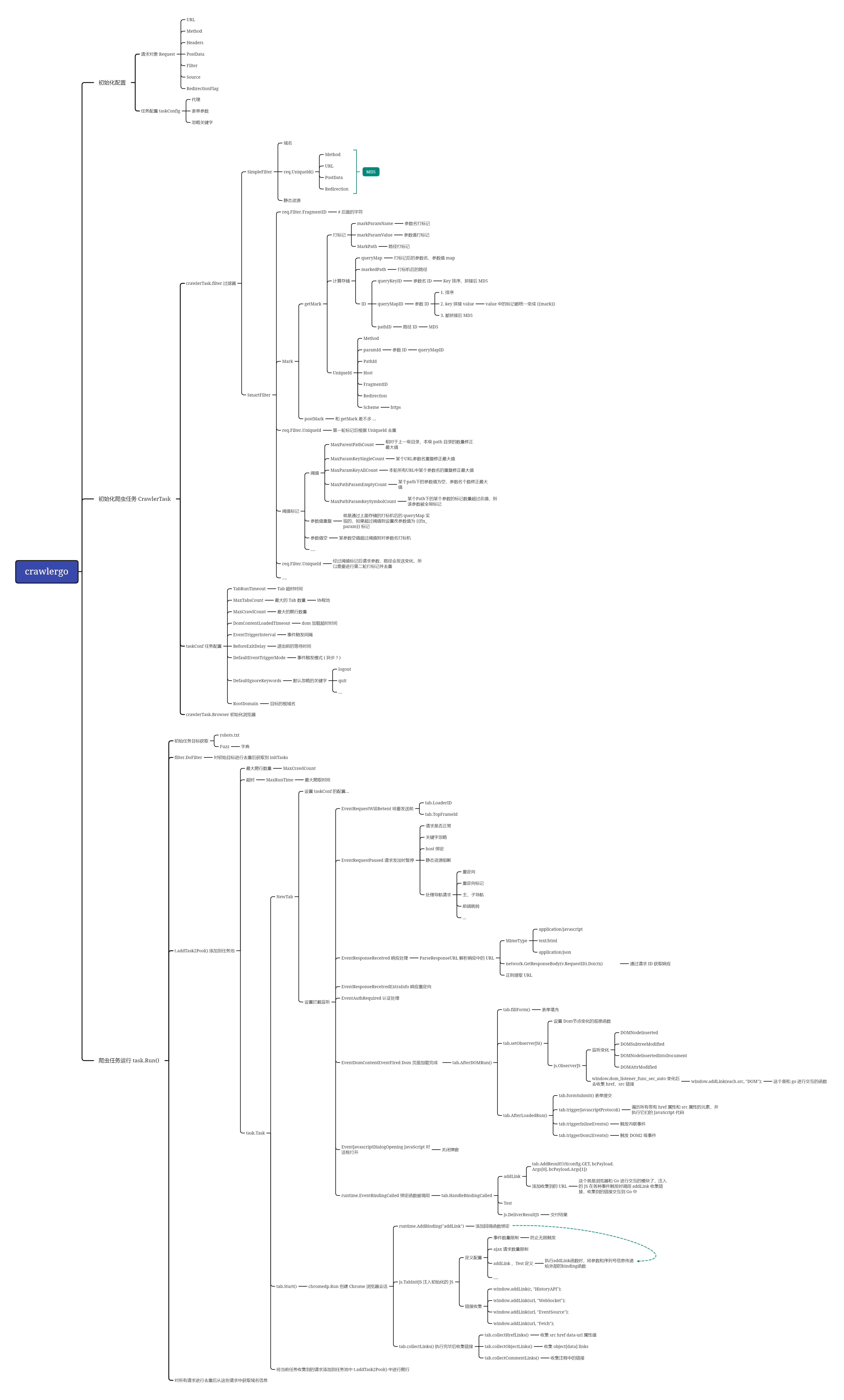
源码学习
跟着 crawlergo 的流程走一遍,具体的逻辑在 pkg/task_main.go 的 Run():
- 通过 robots.txt 获取
- 通过 Fuzz 目录获取
- 收集到的 url 进行过滤后添加到 initTasks 中
- 开始对 initTasks 中的目标进行爬行 addTask2Pool
- 对所有请求进行去重处理
- 从去重后的请求中收集子域名 host
robots.txt 获取:
Fuzz:
DoFilter 这里会先对初始收集到的 url 进行一个过滤,看一下过滤:
这里有两个:
- simple_filter
- smart_filter
simple_filter:
- 域名限制 => 限制爬取的域名
- Unique 去重
- 静态资源
这里的 Unique 是使用的 req.UniqueId() :
看一下这个 UniqueId 是怎么生成的:
这里是根据请求方法 + URL + Post数据进行 MD5 获取的 UinqueId 值。
静态资源过滤:
这里不太明白 JS 为什么要过滤,虽然动态爬虫是去模拟浏览器触发请求,但是 JS 里面也有可能存在一些路径或者敏感信息。
在看一下这个 smart_filter 过滤模式:
- 使用 simple_filter 简单过滤
- 计算 Fragment 的 ID
- 对请求进行打标记
- 通过标记后的 ID 进行去重
- 接下来对标记的 GET 请求进行去重
calcFragmentID:
fragment 就是 # 后面的字符串:
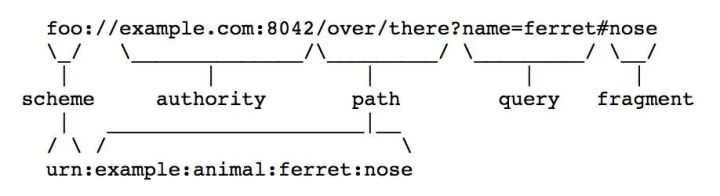
然后就是看看它是怎么去打标记的:
preQueryMark 对原始的请求参数进行预先标记,这里的标记就是通过正则替换:
将请求参数转换为 map:
返回对 map 中的 key 也就是参数名打标记,参数名的标记仅标记过长和纯数字的:
然后是参数值的标记,参数值是可变的所以就肯定是都标记的,这里的标记就是去初始化一个 map 存储 map[参数名]标记值 这样,其他的也是通过正则去进行标记替换,包含的很多模式,非字符类型,字符类型的大小写混合这种,考虑的很全:
之后是去做路径标记,路径标记就直接把匹配到的路径替换为空,然后再设置为标记位:
返回是去生成参数名和参数部分的 ID:
参数名这里就是拼接然后 md5:
参数这里:
计算 Path ID 直接 MD5 :
然后赋值到 Filter 中:
通过请求方法、参数ID、路径ID、Host、FragmentID、协议等组合起来 md5 后作为请求的 uniqueStr
GET 、HEAD 等类型的请求还会做一个重复参数标记,这个其实就是去记录请求参数ID的数量,还有请求ID+参数名[参数值] 的数量
Post 类型的也进行打标记和 Get 的类型:

打完标记后会根据 req.Filter.UniqueId 进行去重
overCountMark 这里就是对参数、路径部分超过最大阈值的去打一个最大标记
处理过超过阈值的部分后会再进行一次打标记,这个时候路径、参数会经过改变,所以会进行再一轮打标记:
然后就是使用新的标记 ID 进行去重处理了:
到这里 crawlergo 的去重部分就完了,它是通过对参数进行打标记进行的去重处理:
简单一下就是这样:
这些会被打标机为:
这样就做到了去重。
过滤之后,会把请求添加到 initTasks 列表中,然后就开始爬行任务了:
IsIgnoredByKeywordMatch 用来判断该请求是否是需要忽略掉的:
然后就是爬行部分:
generateTabTask 就是封装了一下这个请求:
具体的爬行任务就是在 Task() 这里了:
在 NewTab 这里主要是设置请求拦截:
- js 、json 类型的使用 ParseResponseURL 收集页面中可能存在的 url
- 重定向处理
- 认证页面阻塞处理
- 表单填充
- JS 注入
- 回调处理
这里主要看一下 URL 收集的部分:
ParseResponseURL 通过正则去从页面响应中去提取 URL:
然后看下它这里注入的 JS 操作:
表单填充 tab.fillForm() :
看一下是怎么去实现填充的:
获取到 input 之后再去判断需要填充的类型,根据类型选择不同的文本去填充:
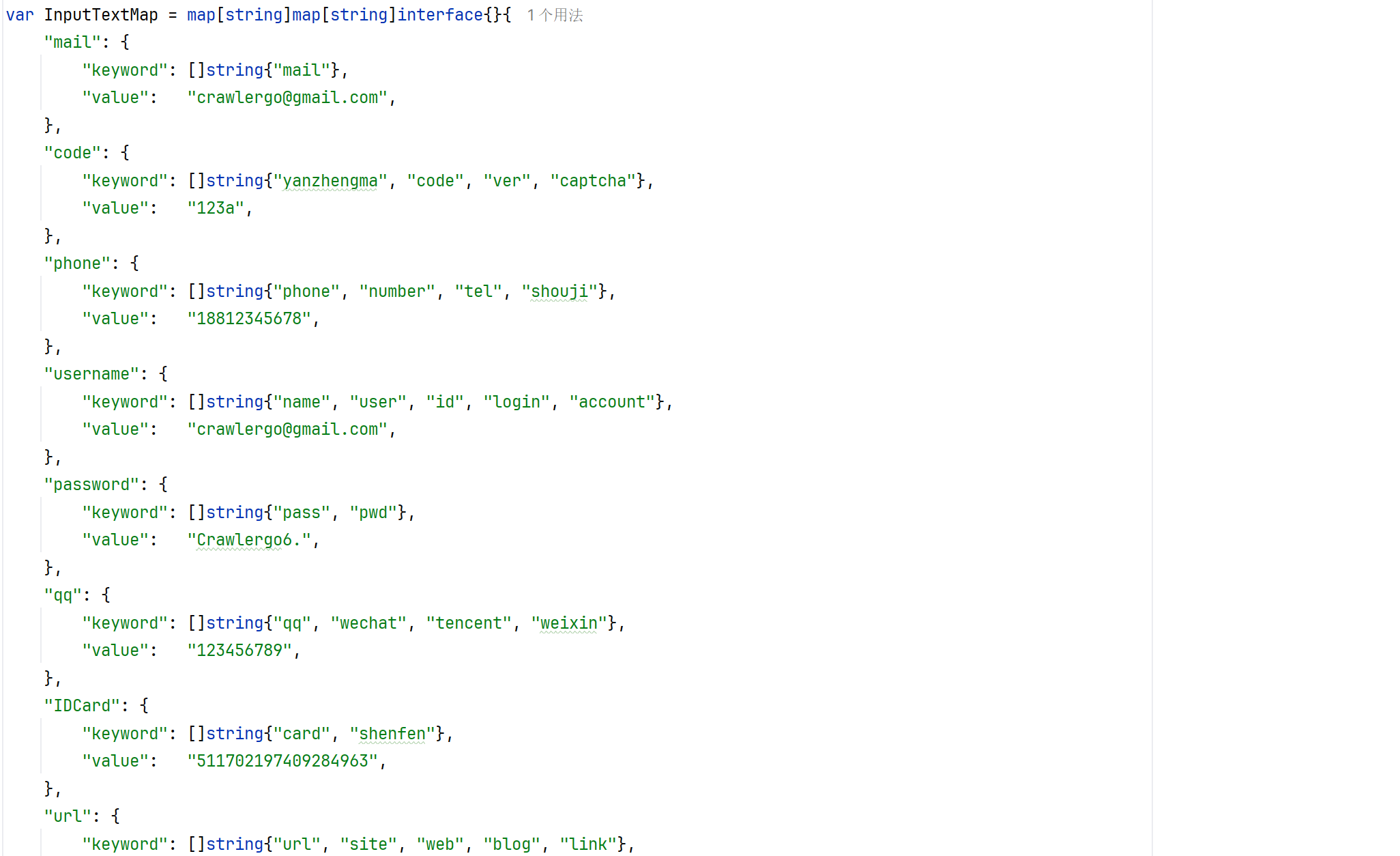
对于单选框,文件上传也做了对应的处理。
之后去注入 JS 去检测 Dom 变化:
JS 如下:
表单填充完毕、Dom 检测 JS 注入之后,它会去调用 AfterLoadedRun 去触发页面的动作,触发动作是通过 JS 去完成的:
看一下用于触发动作的 JS 代码:
triggerJavascriptProtocol:
内联事件:triggerInlineEvents
触发 DOM2 级事件 triggerDom2Events :
事件触发完毕后等待,之后会移除掉监听:
然后是 tab.HandleBindingCalled 这里去进行绑定函数的处理,这里的绑定是 Start() 中 runtime.AddBinding 绑定的函数,其中的 addLink 在 JS 中用的很多,就是各种情况操作都使用它去做链接收集,那就看下这里是如果实现的:
标签页创建完成之后就使用 Start() 开始爬行:
它先去绑定了 addLink、Test 作用如下,主要是用于 go 和浏览器 JS 交互,这里的作用其实就是通过这种方式去收集链接,在 上面的 init_observer_sec_auto_b 和下面的 addTabInitScript 函数中都可以看到链接收集的操作。

然后在加载页面时注入 js.TabInitJS ,该 JS 处理了初始化和各种场景的链接收集操作:
涉及的一些 JS 知识:
- window.navigator.webdriver:用于检测当前页面是否在使用自动化测试工具
- navigator.plugins:返回浏览器的插件列表
- navigator.permissions:提供了对浏览器权限状态的查询和更改的功能
- Histor:接口允许操作浏览器的曾经在标签页或者框架里访问的会话历史记录
- window.history.pushState:向浏览器的历史记录栈中添加一条新的记录,并在不刷新页面的情况下改变URL。这个方法常用于单页面应用程序(SPA)中,可以帮助开发者实现前端路由和用户界面的状态管理
- window.history.replaceState:更改浏览器地址栏中显示的URL,而无需加载新的页面或重新加载现有页面。这对于在Web应用程序中实现单页应用程序(SPA)非常有用,因为可以更改URL并在不刷新整个页面的情况下更新应用程序的状态。
- hash 属性:一个可读可写的字符串,该字符串是 URL 的锚部分,一般有当前页面中 href 中 # 地址触发。hash 即 URL 中 # 字符后面的部分。可以通过 window.location.hash 属性获取和设置 hash 值。window.location.hash 值的变化会直接反应到浏览器地址栏(#后面的部分会发生变化),同时,浏览器地址栏 hash 值的变化也会触发 window.location.hash 值的变化,从而触发 onhashchange 事件。当 URL 的片段标识符更改时,将触发 hashchange 事件。Vue 这种前端框架就是 #/path 的
- window.EventSource:创建一个新的
EventSource,用于从指定的 URL 接收服务器发送事件,可以选择开启凭据模式。这是服务器向浏览器推送信息除过 websocket 的另一种方式 。 - window.fetch:是浏览器提供的用于发起网络请求的API。它是一种现代的替代传统XHR(XMLHttpRequest)的方式,提供了更简洁和强大的请求和响应处理能力。
- window.open:是JavaScript中的一个方法,用于在浏览器中打开一个新窗口或标签页,并加载指定的URL。
- window.setInterval:定时调用的函数,可按照指定的周期(以毫秒计)来调用函数或计算表达式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 | |
之后是做了一个链接收集的操作,就是收集 src href data-url 属性值、 object[data] 、还有注释中的链接
在 Start() 完成之后,它会去把这些收集到的链接再去爬一遍:
再总体简单理一下流程:
task.Run()
- initTasks url 收集
- robots.txt
- Fuzz
- filter.DoFilter 去重
- addTask2Pool 开始爬 => task.Task()
- tab.Start() => 爬行逻辑
- engine2.NewTab => 初始化 Tab 和请求拦截监听
- 响应处理 js、json、html 解析响应中的链接
- 基础认证页面注释处理
- tab.AfterDOMRun()
- 表单填充、提交
- 注入 ObserverJS 收集 src、href 属性值
- 触发事件
- 初始化 chromedp.Run
- runtime.AddBinding("addLink") => 绑定函数,用于 go 和 js 进行交互去收集链接
- 注入 js.TabInitJS 浏览器属性、url 收集( addLink )
- engine2.NewTab => 初始化 Tab 和请求拦截监听
- tab.ResultList 当前页面收集的链接去重再使用 addTask2Pool 去爬
- 所有请求去重
- 从请求中收集域名数据
学习总结
学到的比较多,动态爬虫的具体实现、请求去重的方式、crawlergo 库深入使用、js 的一些知识,准备再看一看静态爬虫,看看它是如何去实现的。