learn-claude-code
前言
既然 AI 目前依旧是提示词 + 工具,那么是怎么把它使用到极致,衍生出那么多的好用的产品呢?
项目:https://github.com/shareAI-lab/learn-claude-code
工具与执行
s01 循环调用工具
One loop & Bash is all you need
The minimal agent kernel is a while loop + one tool
LLM 根据用户需求调用工具,工具执行结果返回给 LLM,LLM 再次决策工具调用,直到完成任务。
1 | |
1 | |
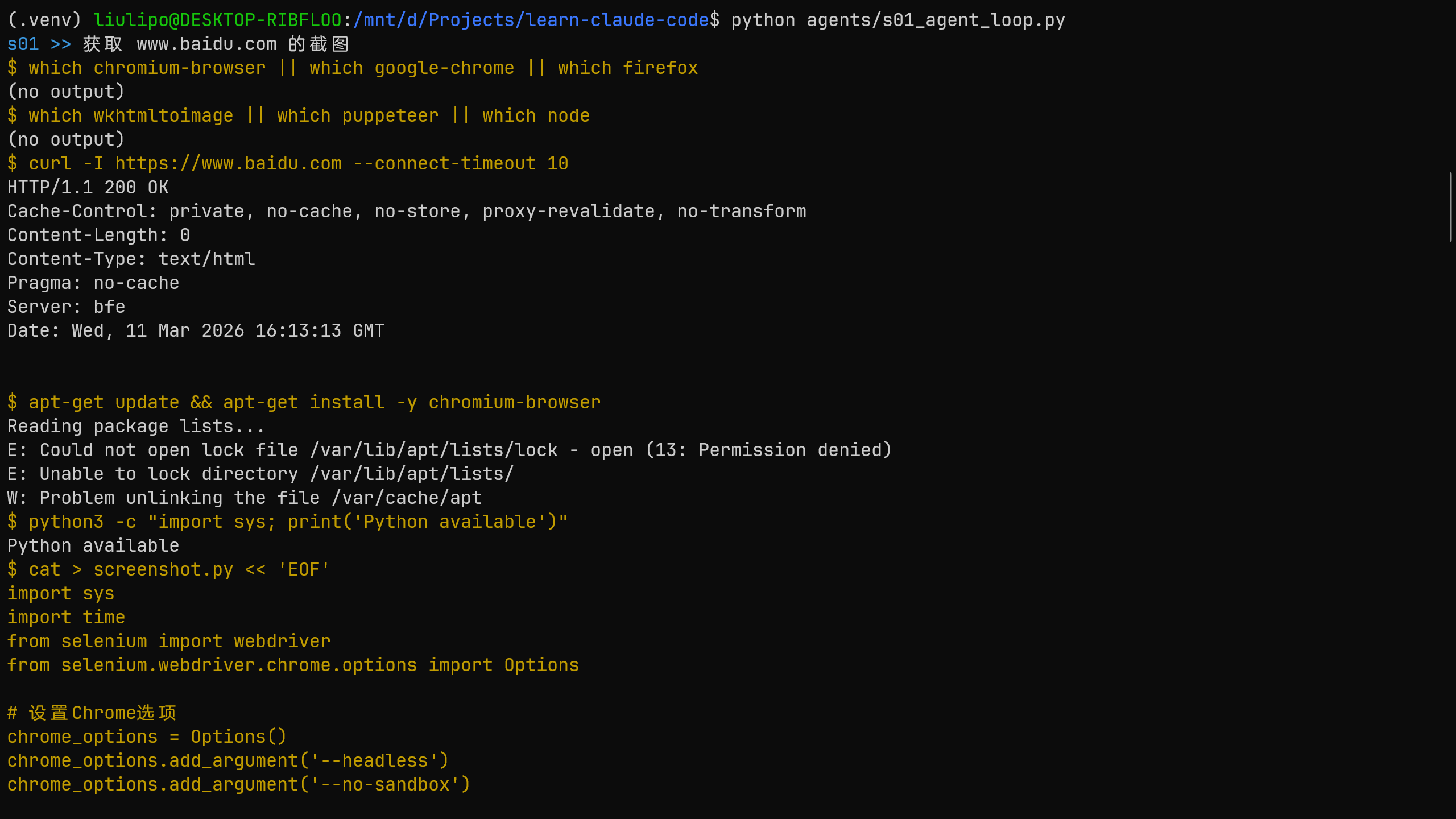
LLM 只能操作一个 bash 工具,用于执行系统命令,System 提示词要求其使用 bash 解决任务,直接行动,不要解释。
理论上来说,通过执行 bash 可以完成大部分的工作,比如通过 echo 写文件、sed 修改文件、cat 查看文件,理论上来说这可以完成所以的事情,因为 LLM 完全可以通过这些功能来编写 python 代码,通过代码再完成更多的事情。
通过 JSON Schema 让 AI 准确的知道输入的参数类型。
1 | |
随后就是循环调用
1 | |
可以看到 AI 的决策过程,最初想直接找相关的 cli 工具完成需求,后面又尝试编写 python 代码,AI 可以完全自主的通过系统命令来解决问题。
s02 多个工具
The loop stays the same; new tools register into the dispatch map
1 | |
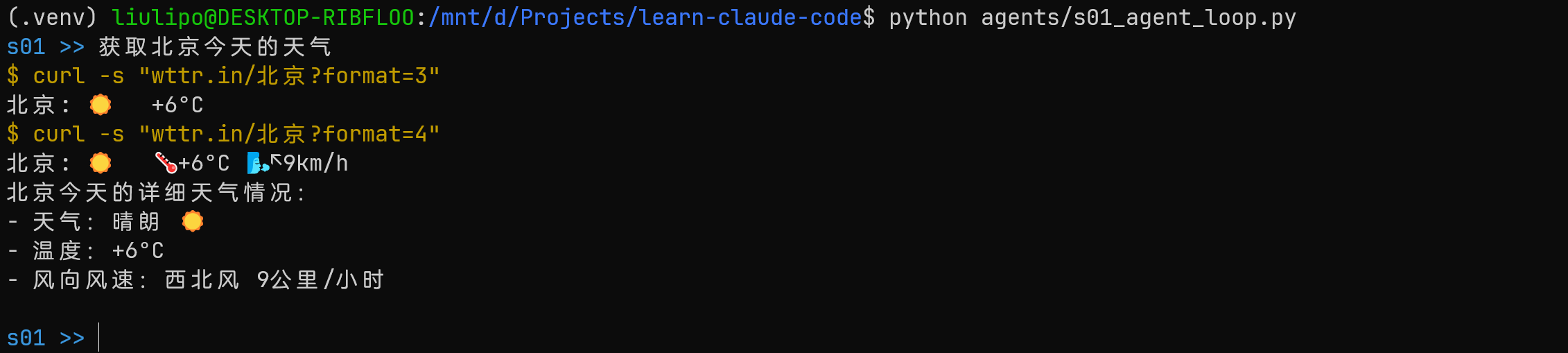
s01 中是直接调用 bash 工具:
1 | |
在 s02 中,增加了多个工具,然后根据 LLM 决策选择处理( {tool_name: handler} ):
1 | |
工具也做出改良,增加了对路径安全的考虑,run_read 工具运行前都需要检测路径:
1 | |
不过嘛,只要 LLM 依旧可以运行系统命令,所谓的路径安全问题其实依旧没有解决,所以 cursor 等客户端才会在运行系统命令的时候需要用户批准:

目前这种情况好像解决方法就在沙箱 Docker、用户批准、低权限这样。
规划与协调
s03 todolist
An agent without a plan drifts; list the steps first, then execute
s03 中,增加了 todo 工具和提醒更新 todo 的提示词注入。
可以让 LLM 有效的对用户的复杂任务做出规划,然后使用 todo 记录,让 LLM 知道目前已经完成的 todo 和还需要执行的 todo。
同时优化系统提示词,使用 todo 工具把任务分成多个步骤,然后在运行前标记正在运行的 todo,运行完成之后标记完成。
1 | |
1 | |
todo 工具:
1 | |
然后在 agent 模块,如果 3 次对话都没有使用 todo 工具更新就注入提示词,提醒 LLM
1 | |
LLM 会先进行规划,然后一步一步完成任务:
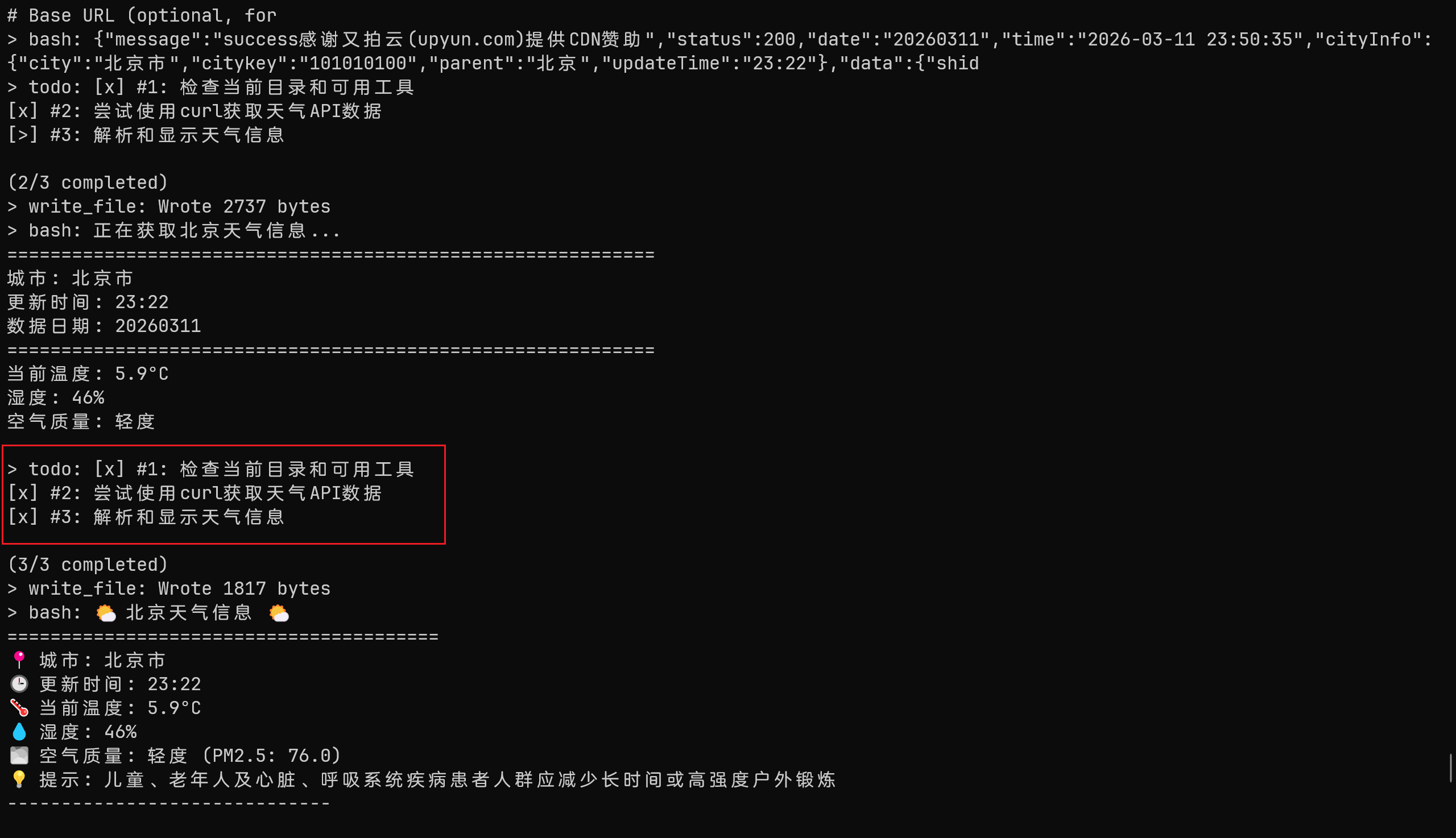
对于复杂任务来说,划分 Todo 会让 LLM 能够完成整个流程,但是对于简单任务来说就会比较麻烦了。
s04 子 Agent
Break big tasks down; each subtask gets a clean context
s04 实现了子 agent 的功能
LLM 使用 task 工具分发任务给子 agent,子 agent 完成任务后总结返回给父 agent。
1 | |
1 | |
父 Agent 只能运行 task 工具来分发任务:
1 | |
子 Agent 完成任务,只返回最终的总结 ———— AI 调用工具就是读取工具执行结果然后总结。
1 | |
s05 按需加载技能
Inject knowledge via tool_result when needed, not upfront in the system prompt
在 System Prompt 中包含技能的名称和描述,完整的技能通过 skill 加载工具来获得。
1 | |
Skill 工具:
1 | |
在系统提示词中注入技能相关的描述信息,告诉 LLM 可以使用 load_skill 获取专业技能:
1 | |
然后 LLM 调用工具读取后的技能详情就会被注入到用户提示词中
1 | |
s07 任务系统
“大目标要拆成小任务, 排好序, 记在磁盘上” – 文件持久化的任务图, 为多 agent 协作打基础。
在 s03 todolist 中,LLM 使用 todo 工具生成 todo 工具,这里的 TODO 就几乎只能按照 todo 一件一件事情做,并不完善。
s07 使用文件存储任务,并且可以支持各种前置依赖。
1 | |
1 | |
内存管理
s06 上下文压缩
上下文就是用户和 AI 对话的所有数据,如果每次都需要把所有的数据都发送给 AI,AI 每次都需要阅读从开始到结束的所有数据。
- System
- Assistant
- User
- Query
- Tool Result
1 | |
第一层压缩的是 tool_result,因为每个 tool_result 的结果都会被 Assistant 读取然后做出总结,所以历史的 tool_result 并不需要完全的全部存储。
- 寻找所有的工具执行结果
- 如果保存的 tool_result 数量 > 3 就把除最新 3 个 tool_result 的结果替换为 “[Previous: used {tool_name}]”
1 | |
第二层压缩使用 LLM 来总结历史对话
- 保存历史对话到本地 jsonl
- 使用 LLM 将历史对话做出总结
- 下一轮对话中告诉 LLM 压缩对话的存储位置和总结
1 | |
在 agent 中每轮对话都先进行压缩,还让 LLM 决定是否压缩
1 | |
并发
s08 后台任务
Run slow operations in the background; the agent keeps thinking ahead
1 | |
线程执行命令,将执行完成的命令推送到消息队列
1 | |
Agent 中会把后台执行的命令注入到消息中:
1 | |
协作
s09 Agent 团队
When one agent can’t finish, delegate to persistent teammates via async mailboxes
在之前的案例中,Agent 都是独立的,s04 虽然有子 Agent,但是子 Agent 的作用就是完成指定的功能返回总结就销毁了。
那么向最近的 OpenClaw 里面那种多个 Agent 是怎么实现的呢?
先看系统提示词,给 Agent 设定一个团队领导的角色,让他产出队员并且通过 inbox 进行通信。
1 | |
队员的提示词中给队员设置名字、角色、工作目录,告诉它使用 send_message 进行工作中的通讯。
1 | |
接着先看 inbox 工具,使用 JSONL 作为通信,发送消息就是写入一行消息到对方的信箱,读取就是读取 jsonl 文件然后清除,还有广播全部发送
1 | |
团队
leader 创建队员 agent 以线程的方式一直运行,队员 agent 除了初始化的 prompt 之外还会阅读信箱,接收新的调用。
一个队员 agent 同时只完成一项工作,完成后变成清闲状态才可以再次接收新的任务。
1 | |
这样就很强了,AI 作为 leader 创建各种团队队员 agent,队员 agent 会一直存在,各种 agent 通过信箱通信。agent 完成任务后就给 leader agent 发送消息,leader 读取信箱然后再安排任务。这样就可以让 AI 能够独立自主的完成复杂的项目。
而不是 s04 中的子 agent 完成单项任务后就返回给父 agent 之后就销毁。
s10 团队协议
One request-response pattern drives all team negotiation
s09 中 leader 下方任务后,teammate agent 库库干活,但是很多事情是需要 leader 进行决策,也就是批准 OR 拒绝。
s10 中定义了两种协议,停工和计划批准,通信依旧是使用 jsonl inbox,但是增加了 request_id ,接收方决定批准还是拒绝会给出响应,携带相同的 request_id。
- Lead 派生 teammate
- teammate 工作的时候想 lead 发送消息请求批准
- lead 读取 Inbox 接收到信息进行决策批准 OR 拒绝,给出响应
由于通信依赖的还是 jsonl,所以会设置锁,防止并发写入。
1 | |
先看系统提示词,leader 通过停工和计划批准两种协议管理团队成员
1 | |
队员的提升词,增加了两种协议
- 提交的计划经过批准后才能工作
- 回复停工请求
1 | |
teamment 增加了停工响应和计划请求批准的工具:
1 | |
leader 层面添加了停工请求和计划批准响应的工具
1 | |
s11 自主 Agent
Teammates scan the board and claim tasks themselves; no need for the lead to assign each one
teammate Agent 在空闲状态的时候会自己去任务面板认领任务。
1 | |
Lead 提示词,告诉 LLM 队员是自主的,它们会自己认领任务。
1 | |
任务面板的工具:
1 | |
防止上下文压缩后 teammate agent 忘记身份,重新注入:
1 | |
teammate agent 的提示词中,告诉 agent 自主去认领任务。
1 | |
teammate agent 在空闲的时候
1 | |
s12 Worktree + 任务隔离
Each works in its own directory; tasks manage goals, worktrees manage directories, bound by ID
每个 agent 的任务都有独立的 git worktree ,用任务 ID 管理。
1 | |
Lead 的提示词,告诉 LLM 对于并行或者危险的变更就创建一个 git worktree,然后在内部做各种操作。
1 | |
git worktree 可以让一个 git 仓库同时拥有多个可以独立操作的工作目录,共享一个 .git。
多个 agent 各干各的,互不干扰。不会因为其他 agent 的更改产生问题。
事件跟踪:
1 | |
worktree 管理,使用一个 JSON 文件
1 | |
结语
提示词 + 工具感觉被玩出花来 666