xscan 旧版本在知识星球开源了,看一看,主要看 XSS 检测逻辑
项目结构 1 2 3 4 5 6 7 8 9 10 11 12 xscan-1.2 / / xscan/ / / / / / / / /
源码学习 队列模块 core/queuecore/queue/leveldb_queue.go => 基于 goleveldb 的数据存储core/queue/queue.go => Go 实现队列数据结构syndtr/goleveldb: LevelDB key/value database in Go. leveldb_queue.go 封装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package queue import ( "github.com/syndtr/goleveldb/leveldb" "sync" ) type LevelQueue struct { func NewLevelQueue () error ) { "./db/block.db" , nil ) if err != nil { return nil , err return &LevelQueue{Db: db, lock: sync.Mutex{}}, nil func (l *LevelQueue) func (l *LevelQueue) byte ) error { return l.Db.Put(v, nil , nil ) func (l *LevelQueue) int { nil , nil ) 0 for iter.Next() { 1 return index
爬虫模块 xscan 采用的是静态爬虫 + 第三方的 Wayback,和之前看过的 gospider 类似不过也有不同。
静态爬虫 core\spider\spider.gofeed() 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 func (c *Crawler) var wg sync.WaitGroup make (chan SpiderOutput) func (i interface {}) defer p.Release() go func () 100000 0 nil , nil ) for iter.Next() { if index > maxSize { break nil ) 1 close (c.feedChain) for r := range c.feedChain { if c.callback != nil { 1 ) 5 )
就是一个不断深入爬取的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func (c *Crawler) nil , nil ) if err != nil { return "Referer" ) if referer == "" { "Referer" , p.Input) if err != nil { "spider请求失败:%s" , req.URL.String()) return
handleResult 逻辑可以看出 1.2 的静态爬虫比较简陋,只是 href 和表单,和 gospider 有差距。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 func (c *Crawler) if err != nil { "goquery解析失败" ) return "[href]" ).Each(func (i int , s *goquery.Selection) "href" ) if ok { if c.filterUrl(urlString, httpx.GET) { return "href" , "" , "form[action]" ).Each(func (i int , s *goquery.Selection) "action" ) "method" ) if !ok2 { "GET" if ok { if c.filterUrl(action_url, method) { return "input[name]" ).Each(func (i int , selection *goquery.Selection) "name" ) "value" ) if !exist { return if !exist2 { 4 ) "Content-Type" , "application/x-www-form-urlencoded" ) "form" ,
不过整体的爬虫队列是基于 leveldb 文件存储实现的,而不是都在内存中,这个可以借鉴。handleResult 获取到的链接都封装为 SpiderOutput 然后放到队列中,feed() [2] 处的协程会拿出来再丢给回调函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func spiderCallback (out spider.SpiderOutput) "URL" , out.Output).WithField("Input" , out.Input).Debugln() var postdata []byte if out.Body != "" { byte (out.Body)
第三方 在 core/spider/source.go 中定义了通过 web.archive.org 来获取链接,不过好像并没有使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func getWaybackURLs (domain string ) string , error ) { "http://web.archive.org/cdx/search/cdx?url=%s/*&output=json&collapse=urlkey" , domain), if err != nil { return []string {}, err if err != nil { return []string {}, err var wrapper [][]string make ([]string , 0 , len (wrapper)) true for _, urls := range wrapper { false continue append (out, urls[2 ]) return out, nil
解析模块 html core/parser/html/parser.go
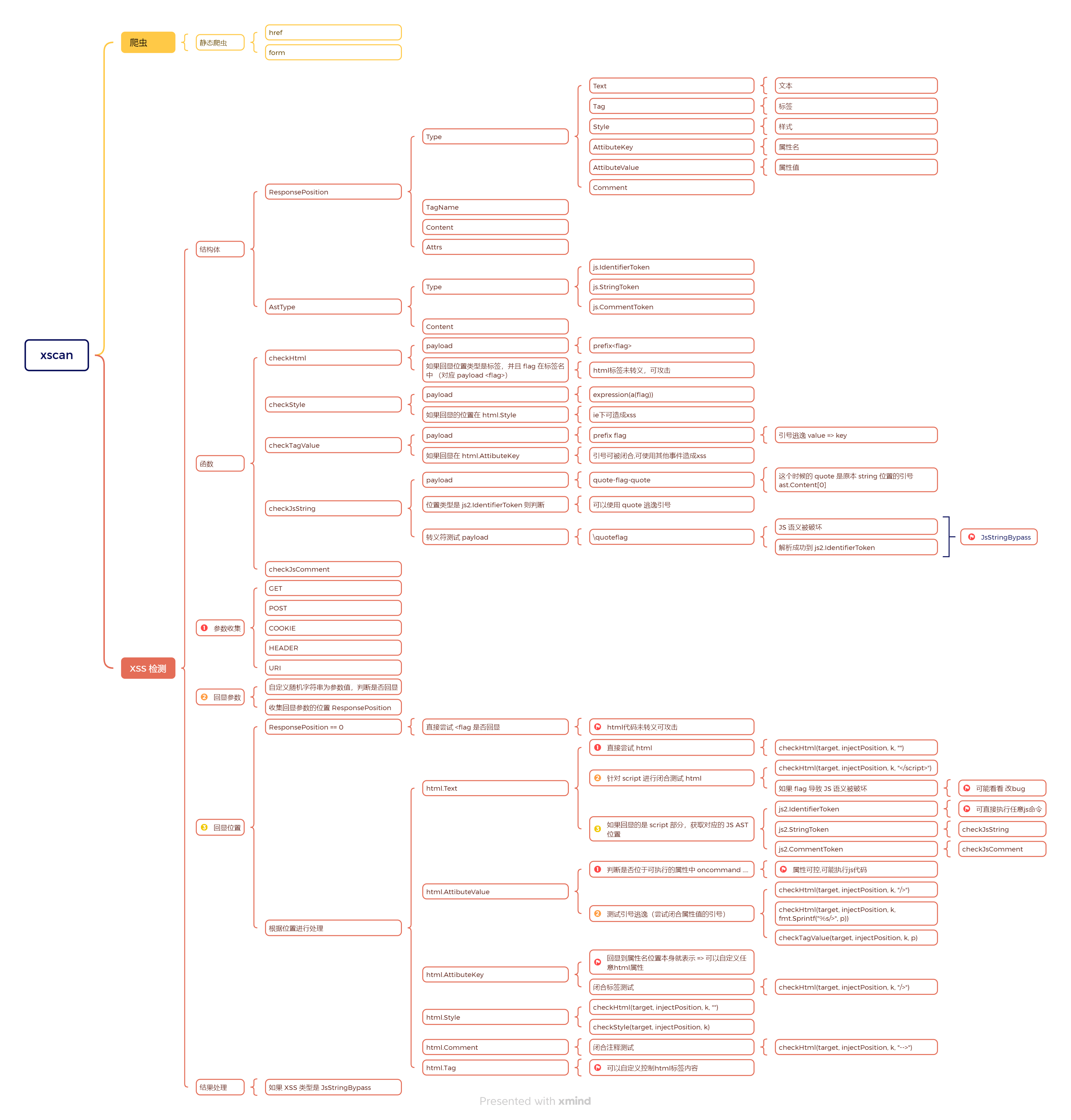
1 2 3 4 5 6 type ResponsePosition struct { int string string
ParseHtml 解析 HTML 返回 ResponsePosition 列表,主要使用到 html.NewTokenizer 进行解析。html package - golang.org/x/net/html - Go Packages
1 2 3 4 5 6 7 8 9 const (iota
ParseHtml 函数用来解析整个 HTML 把 HTML 转换为 ResponsePosition 的格式 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 func ParseHtml (body io.Reader) var positions []ResponsePosition var tokenizer []ResponsePosition for { switch tt { case html.ErrorToken: break labelType case html.SelfClosingTagToken: string (z.Raw()) for i, attr := range attrs { if attr.Val == "" { continue if kIndex != -1 { 1 if vIndex > -1 && (raw[vIndex] == 34 || raw[vIndex] == 39 ) { 2 +len (attr.Val)] "" , append (positions, current) case html.StartTagToken: string (z.Raw()) for i, attr := range attrs { if attr.Val == "" { continue "=" if kIndex != -1 { 1 if vIndex > -1 && (raw[vIndex] == 34 || raw[vIndex] == 39 ) { 2 +len (attr.Val)] "" , append (positions, current) case html.TextToken: if len (positions) > 0 { len (positions)-1 ].Content += string (z.Raw()) case html.EndTagToken: if len (positions) > 0 { len (positions) - 1 append (tokenizer, current) case html.CommentToken: "comment" , nil , append (tokenizer, current) for len (positions) > 0 { len (positions) - 1 append (tokenizer, current) return tokenizer
SearchInputInResponse 方法用于获取报告知道输入的 ResponsePosition 列表:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 func SearchInputInResponse (input string , body io.Reader) error ) { var ret []ResponsePosition for _, p := range tokenizer { if strings.Contains(p.Content, input) { if p.TagName == "comment" { append (ret, ResponsePosition{ else { append (ret, ResponsePosition{ if strings.Contains(p.TagName, input) { append (ret, ResponsePosition{ if strings.ToLower(p.TagName) == "style" && strings.Contains(p.Content, input) { append (ret, ResponsePosition{ for _, attr := range p.Attrs { if strings.Contains(attr.Key, input) { append (ret, ResponsePosition{ if strings.Contains(attr.Val, input) { append (ret, ResponsePosition{ return ret, nil
JS https://zhaomenghuan.js.org/blog/js-ast-principle-reveals.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func ParseJs2AstType (src string ) error ) { var ret []*AstType for { switch tt { case js.ErrorToken: if l.Err() != io.EOF { return ret, err return ret, nil default : string (text), append (ret, &n)
SearchInputInScript 主要是收集这几种类型:
IdentifierToken:标识符(变量名、函数名、属性名等)StringToken:字符串,比如 let s = "hello" 中的 "hello"CommentToken:注释内容
这里用到了 fallthrough ,go 的 switch case 不需要显式的跳出,默认会跳出,fallthrough 的作用就是不跳出,继续向下。不过这里就这 3 个感觉也没必要这么写,可能是方便后续扩充。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 func SearchInputInScript (input string , script string ) error ) { if err != nil { return nil , err var ret []*AstType for _, token := range astTokens { if !strings.Contains(token.Content, input) { continue switch token.Type { case js.IdentifierToken: fallthrough case js.StringToken: fallthrough case js.CommentToken: append (ret, &n) default : return ret, err return ret, nil
变量收集,对应着隐藏参数收集,就是从 HTML 中收集一些静态爬虫没有收集到的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 var regx = regexp.MustCompile(`^[\w\d-_]+$` )func (w *varWalker) switch n := n.(type ) { case *js.VarDecl: for i := range n.List { if !ok { continue string (v.Data) if regx.MatchString(strV) { append (w.vars, strV) case *js.ObjectExpr: for _, p := range n.List { if p.Name != nil { if regx.MatchString(v) { append (w.vars, v) return w
XSS检测模块 HTML 每个函数对应不同的 XSS 检测方法:checkHtml html标签未转义,可攻击 :
flag 生成payload 生成 prefix<flag>发起请求
搜索 flag 在 html 中的位置
如果 flag 在标签名里面则判断存在 => 之前的 payload 的 flag 就是一个标签
checkStyle ie下可造成xss :
payload:expression(a(%s)) => expression 用于在 IE 中的 CSS 样式中镶嵌 JS 代码如果位置是样式,并且内容包含 expression 表达式则判断存在
checkTagValue 引号可被闭合,可使用其他事件造成xss
这次检索的是标签里面属性中存在的 XSS
payload:fmt.Sprintf("%s%s", prefix, flag) => 这里的前缀其实就是引号啥的如果属性的 key 中包含 flag 就判断存在 => 之前是的属性值位置,现在通过引号进行闭合,变成了 key 的位置。a="payload" => a="" flag
代码都差不多:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func (r *RefXss) string , k string , prefix string ) { "%s<%s>" , prefix, flag) if err != nil { "请求失败[checkHtml]" ) return if err != nil { "html语义解析失败" ) return for _, p := range positions { if p.Type == html.Tag && strings.Contains(p.TagName, flag) { "html" , "html标签未转义,可攻击" , "%s=%s" , k, payload), "%s=%s" , k, prefix+"<svg onload=alert(1)>//" ), append (r.result.Items, item)
JS checkJsString JS 逃逸 应该是在 script 里面的变量什么的可控的场景
payload := fmt.Sprintf("%s-%s-%s", quote, flag, quote)HTML 解析,获取 script 标签的内容(JS代码)
解析这些 JS 代码获取语法树
如果 ast.Type 是 IdentifierToken 并且内容中有 flag 则 可以使用quote逃逸引号
如果没有逃逸成功,进行转义测试 fmt.Sprintf("\\%s%s", quote, flag)
JS AST 解析失败,表明使用转义符破坏原有语义
解析成功,和 [4] 处类似的检测方式
checkJsComment 可以使用%s逃逸注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 func (r *RefXss) string , k string , s string ) { var payload string var truePayload string if s == "//" { "\n%s//" , flag) "\n%s//" , "alert(1)" ) else if s == "/*" { "*/%s/*" , flag) "\n%s//" , "alert(1)" ) if err != nil { "请求失败 [checkJsComment]" ) return string {} for _, p := range positions { if strings.ToLower(p.TagName) == "script" { append (sources, p.Content) "\n" ) if err != nil { "ast解析失败" ) return for _, ast := range asts { if ast.Type == js2.IdentifierToken && strings.Contains(ast.Content, flag) { "Js CommentToken" , "可以使用%s逃逸注释" , truePayload), "%s=%s" , k, payload), "%s=%s" , k, truePayload), append (r.result.Items, item) return
XSS request 模块:针对对应位置设置对应的请求参数,请求用的 projectdiscovery 的库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 func (r *RefXss) string , k string , v string ) (*retryablehttp.Request, *httpx.Response, error ) { if err != nil { return nil , nil , err switch position { case InjectGetParameter: case InjectPostParameter: string (target.POST)) if err != nil { return nil , nil , err if err != nil { return nil , nil , err case InjectCookieParameter: for i, vv := range cookies { if key == k { "Cookie" , EncodeCookies(cookies)) case InjectUriParameter: "/" ) "." ) if last > -1 { "/" ) case InjectHeaderParameter: if err != nil { return nil , nil , err return req, resp, nil
扫描模块:
隐藏参数收集
HTML 获取 input 的 name
JS AST 获取变量再配合正则进行过滤
添加隐藏参数,调用 handle 进行扫描,只检测 GET
检测其他位置的 XSS ( POST, COOKIE, HEADER, URI )
总结 AST 抽象语法树